AI活用による人的資本データ収集の効率化に挑戦

この記事はQiitaからの転載となります
この記事は株式会社カオナビ Advent Calendar 2024の22日目の記事です。
https://qiita.com/advent-calendar/2024/kaonavi
著者紹介
はじめまして。株式会社カオナビ 本江雄人と申します。
普段の業務ではデータ分析チームを立ち上げ、社内のあらゆるデータを収集しステークホルダーの意思決定をサポートする業務をしております(参考:DevOpsDays2024 登壇資料)。
https://speakerdeck.com/kaonavi/example-of-data-management-startup-in-kaonavi
今回はその業務から少し離れておりますが、兼務として今年実施させていただいた、AIを活用して人的資本データ収集の効率化に挑戦した事例をご紹介いたします。
1. 人的資本データnavi について
▼ 人的資本データnavi とは
約3,900社の人的資本開示情報を収集・一覧・分析できる人的資本データベースで、企業の人材戦略指標をグラフや一覧で簡単に比較・検索できるサイトです。
同業他社との比較や業界全体の現状を把握することができ、人事部門の方々が人材戦略の目標設定や改善策の検討をするのに活用されています。
https://hc-datanavi.kaonavi.jp/
▼ データソースに関して
人的資本データnaviでは、企業の有価証券報告書(有報)をEDINETから収集し、人的資本開示情報を抽出し収集しています。
https://disclosure2.edinet-fsa.go.jp/week0010.aspx
2.従来のデータ収集方法と自動化による成果
▼ 有価証券報告書データ収集方法の変化と改善
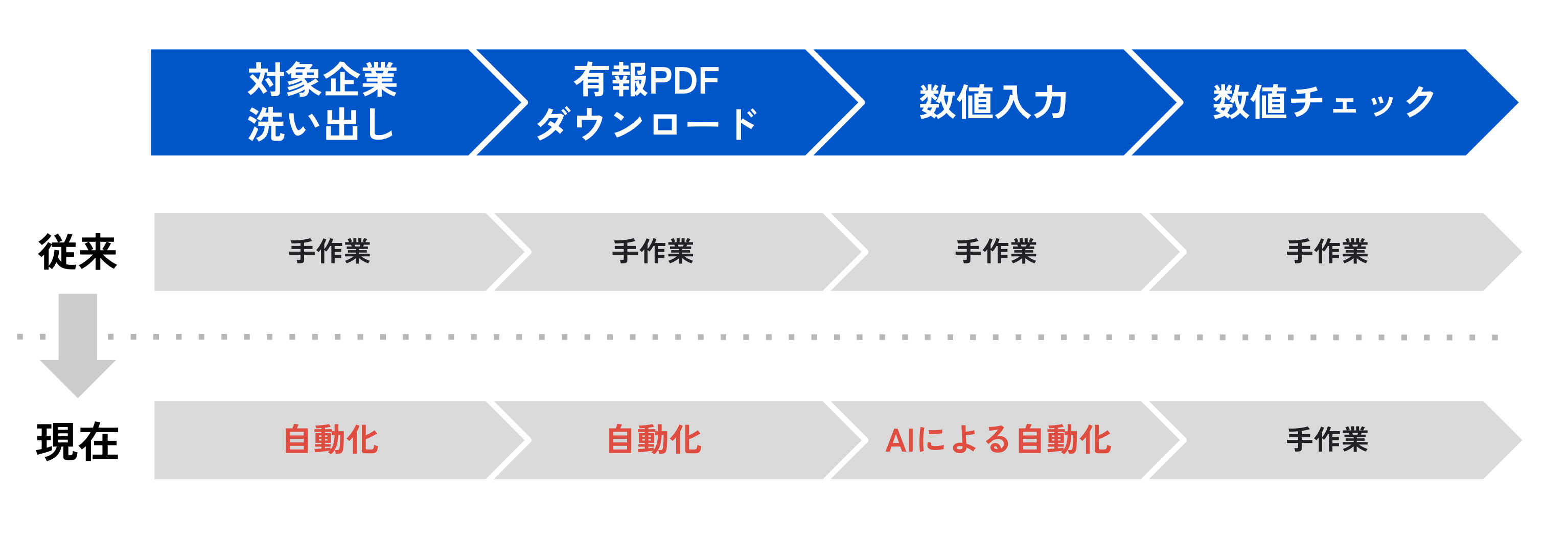
- 対象企業の洗い出し、有報PDFのダウンロード、数値入力を自動化を実施することで、データ収集の効率化(収集速度向上と費用削減)を実現
- 数値チェックの体制に関しては、当社の専門スタッフによるデータチェックを従来どおり実施し、情報の正確性と信頼性の維持向上に努めています
3. AI活用の挑戦をした背景
▼ データソースが構造化されておらず絶望的であり、自動化をあきらめていた
EDINETからのデータ取得は何パターンかあり、CSVやPDFの形式が選べます。法律で開示義務が発生する項目などは当然データはCSVで構造化されており、「すぐに値が取得できるだろうなー」と思ったのですが、現実はそう甘くはありませんでした。以下の画像を見てください。
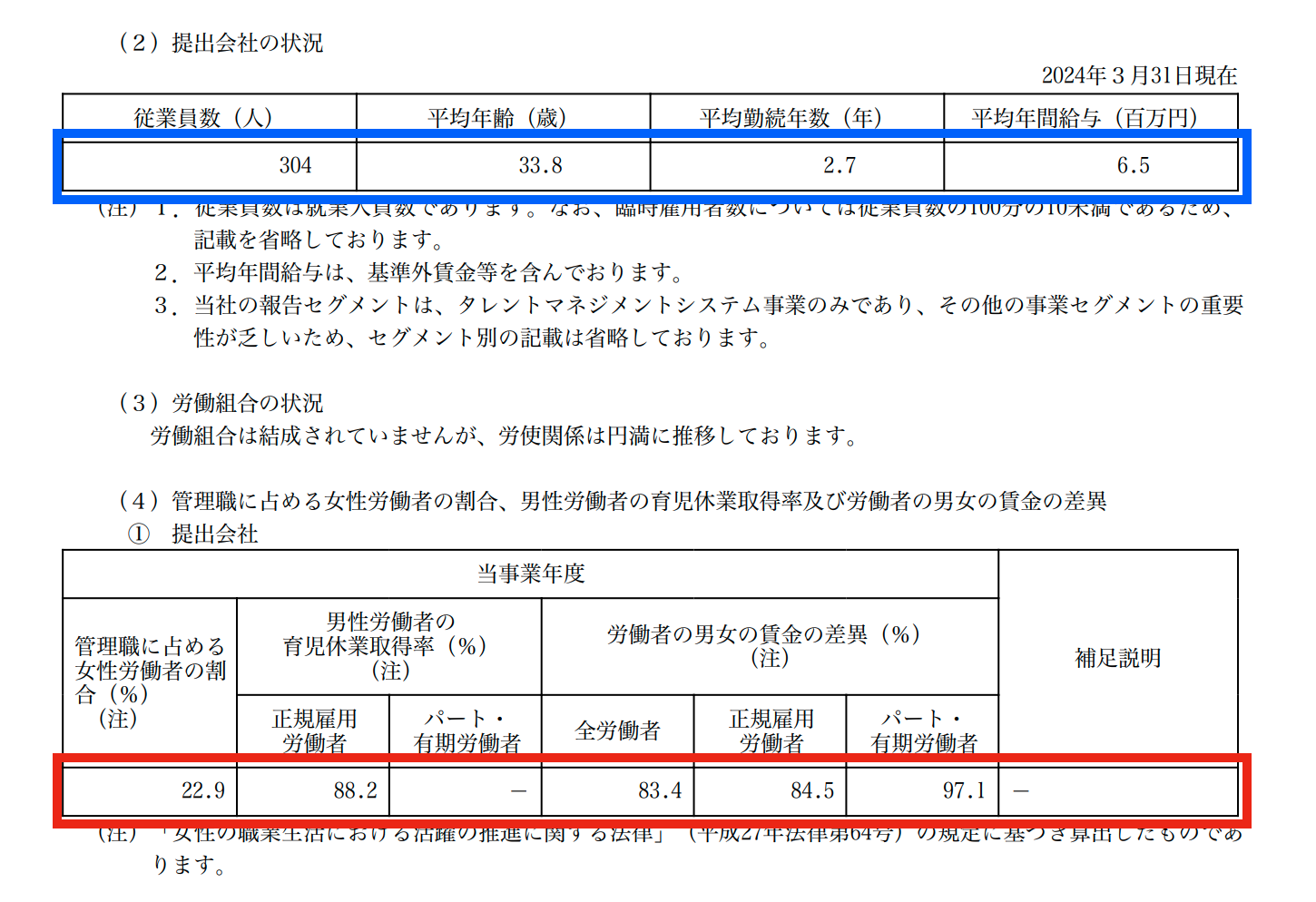
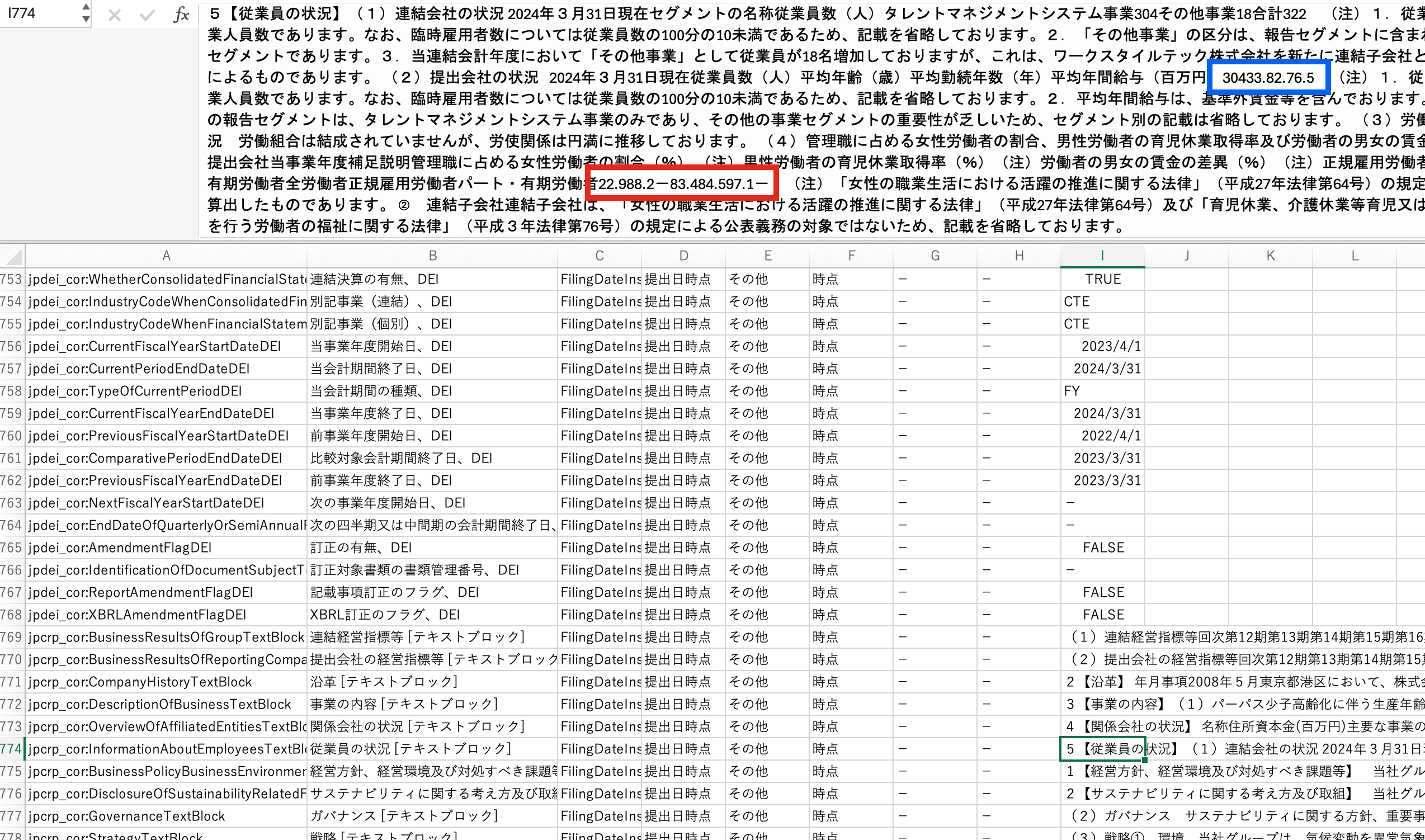
- フォーマットがまったく一緒というわけではない
- 改行やスペースをTrimしており、2つの数字がくっついており、形態素解析とか使ってもうまくいかないことが想像できる(図の青と赤の四角で囲った部分)
絶望的と判断し、自動化しておりませんでした。
▼ 社内のAIチャットボットを利用している中で、AIの進化を感じた
セキュリティなどを考慮した、社内で利用できるAIチャットボットが弊社には存在します (2023/12/01 - 今年1年でCTOとして取り組んできたこと - AIチャットボット「ナービィ」導入) 。
この社内で利用できるAIチャットボットですが、とあるLLMモデルへと頭脳が変化したタイミングで、返答内容も一段と賢くなったように感じた瞬間があり、「これなら、人的資本データの取得もできるのでは?」とチャレンジすることにしました。
4. AI活用においてのプロンプトの工夫
結構単純ではありますが、プロンプトの工夫のいくつかをご紹介します。
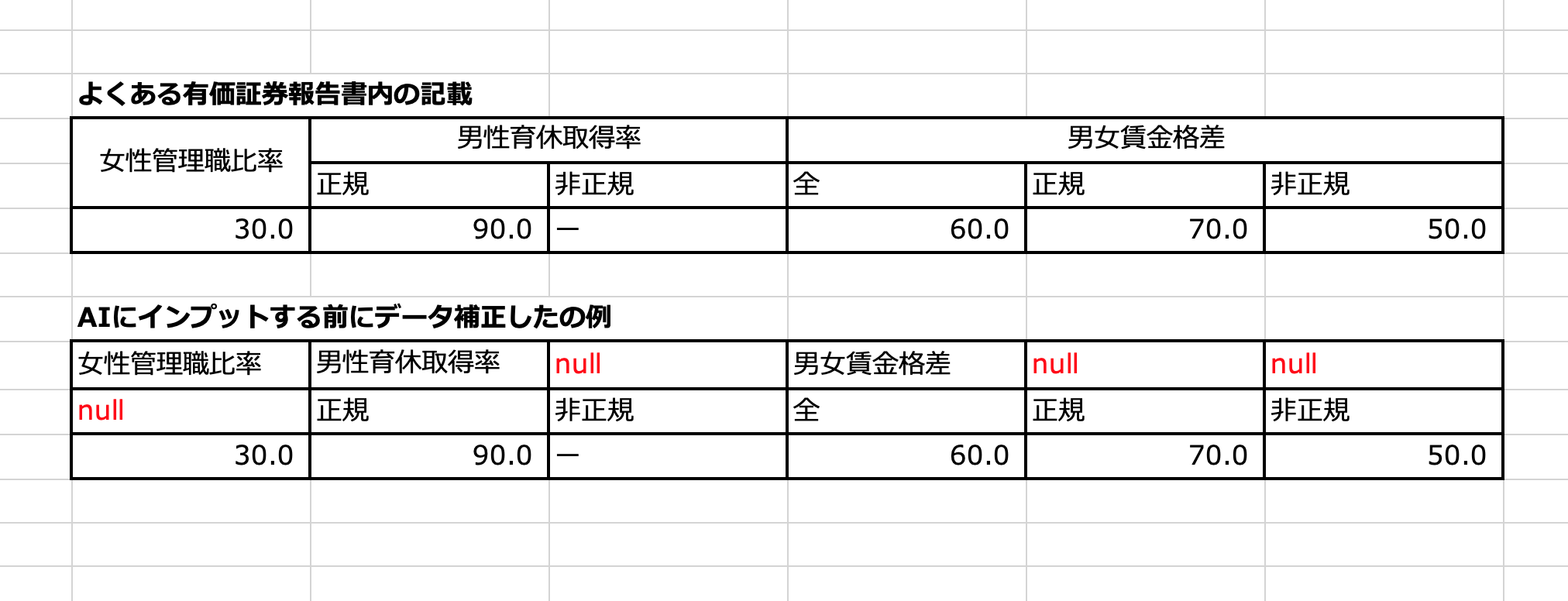
▼ セル結合された表のに弱いと言われるLLM,セル結合しなかった場合のデータ構造に変換してあげれば精度があがるのでは?
特になにも考えずに有価証券報告書のデータを読み込ませるところから挑戦はスタートしたのですが、セル結合された表がたくさんでてくる有価証券報告書のPDFにおいて、かなり間違った数字の取得をしてしまっていました。ググってもかなり「セル結合はAIと相性が悪い」という記事が多くでてきました。
単純にセル結合前どんな感じのデータ構造になっているのかを考慮し、PDF上の表のデータを構造化してあげたら、かなり正答率が上昇しました。
▼ とにかくプロンプトも構造化、矛盾を減らす
人的資本データnaviをご覧いただけるとわかるのですが、とにかくさまざまな項目を取得しております。naviで利用しているデータ以外も様々取得しているのですが、とにかく問いかけ自体を構造化して出力の精度を上げました。
- 指標Aの記載はありますか?
- 指標Aの値を教えてください
↓
- 指標Aについて
- 記載はありますか?(はい/いいえ)
- 記載がある場合、その値を教えてください
「記載がない」のに「値を入力されている」などの矛盾がかなり減りました。
だた並列に質問を並べるだけの場合、同じ項目に関する質問だとAI側が判断できずに、全部の質問に愚直に文脈から推し量ろうとしてて矛盾の起こる結果を返答してきていたのかもしれません
▼ 前提条件などのインプットは確かに効果がありそうだ(ペルソナプロンプト、前提条件を詳細に記載)
一般的によくいわれるプロンプトのテクニックも含めて、試してみました
- ペルソナプロンプト :AIに特定の人物や専門家の役割を与え、より文脈に沿った答えを引き出す手法
- 事前情報のインプット:なにをしてほしいのか、どのような前提の理解をしてほしいのかなど文脈理解を向上させる効果
前に書いた工夫よりは劇的にといった感覚値はなかったですが、それなりに効果があったと感じました。「このデータって有価証券報告書で、その年の経営状況や人的資本指標の数値が記載されているものです。」と前提を伝えて指示出ししました。
5.AIを利用した業務を実施した感想や学び
▼ AIを「手懐ける」という工数をどうプロジェクトの計画に組み込むか?
カチッと in/out を考えてシステムをつくるタイプのプロジェクトと違い、すこし出力に揺れがあったりするのが難しいポイントでした。
チューニングまわりに余裕をもった計画を立てる or 期間を決めないと、ずっとチューニングを頑張っちゃってムダに工数を使ってしまう
といった部分が肝かと思います。
▼ 次回データ収集時は、もちろん最新モデル試してみるよね
毎年のように新しいモデルがでてくるので、次回実施時は確実に最新モデルを試すことにはなるでしょう。
正答率が上がっていったら 「何もしてないのに改善した!」 となるのですが、果たしてどのような結果になるでしょうか?来年が楽しみです。
▼ 非構造化データはやっぱり分析しにくいよね
メインの業務がデータ分析基盤の運用とデータ活用の推進を実施しているのもあり、感じたことがあります。
正直、EDINETのデータがかなり分析するには厳しい構造をしているなと思いました。
自分のデータエンジニアリングの業務では基本は構造化データ、半構造化データでのデータ収集をしていく方向になるかとおもいます。
ただ、「どうしても」みたいな場合にAIを使って非構造化データを何かしら分析しやすい形に変形するという経験は今後データエンジニアリングの文脈でも活用しうる一つの武器かな ともおもいますので、いい経験ができたなと思っています。
今回は有価証券報告書のデータ収集の効率化・コスト減をお話させていただきました。 今後もさまざまいろいろな業務の改善をしていくと思うので、どんどんAIを活用していきたいなと思っています。
今回みたいにとある正解の数値を抜き出すみたいな業務よりも、要約とか集計とかの業務がAIは得意な気がするので、まだまだやれることはたくさんありそうです。
がんばります。